第一篇博客里答应的,第二篇会用
pymysql直接将数据存入 MySQL 数据库。 代码部分只注释了数据库操作的部分,爬虫部分有时间会补上。
网易科技频道 以独特视角呈现科技圈内大事小事,内容包括互联网、IT业界、通信、趋势、科技访谈等。 下面以 网易科技-智能 首页为例,爬取文章的【链接–标题–发布时间–作者来源–具体内容】等信息并存入MySQL:
网页分析
按【F12】键进入谷歌浏览器开发者工具,查看 Network – All:
 点击【加载更多】按钮则出现第二个 smart_datalist.js ,对比观察 URL 的不同可直接构造用于翻页。
点击【加载更多】按钮则出现第二个 smart_datalist.js ,对比观察 URL 的不同可直接构造用于翻页。
smart_datalist.js 中的内容包含 json 格式的数据:
 后续再逐一访问每篇文章的 docurl ,获取全文即可。
后续再逐一访问每篇文章的 docurl ,获取全文即可。
安装配置 MySQL
网上教程很多,请自行百度或Google。
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
爬取【网易科技-智能】频道首页的【今日热点】文章,并存入MySQL数据库
@Update: 2019-03-20
@Author: Newyee
@Python: 3.6.5
@MySQL : 8.0
"""
import requests
from lxml import etree
import re
import time
import pymysql
headers = {'User-Agent': 'Mozilla/5.0 (Windows x86; rv:19.0) Gecko/20100101 Firefox/19.0'}
pattern = re.compile(r' {20}(原标题.*)\n {16}') # 用于删除文章开头的“原标题”内容
def get_html(url):
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except Exception as e:
print(e)
return 'Error'
def get_content(doc_url):
try:
text = get_html(doc_url)
html = etree.HTML(text)
contents = html.xpath('//div[@class="post_text"]//p/text()')
content = ''.join(contents)
content = re.sub(pattern, '', content)
return content
except Exception as e:
print('Get content Error:', doc_url, e)
def main(urls):
# 打开数据库连接(具体配置信息请自行替换)
db = pymysql.Connect(
host = 'localhost',
port = 3306,
user = 'root',
password = 'root',
db = 'test',
charset = 'utf8')
# 建表语句
sql_create = "CREATE TABLE IF NOT EXISTS wangyi_tech (id INT(5) NOT NULL AUTO_INCREMENT," \
"url VARCHAR(265),title VARCHAR(265),time VARCHAR(265),source VARCHAR(265),content VARCHAR(10240),"\
"PRIMARY KEY (id) ) DEFAULT CHARSET=utf8"
# 创建一个游标对象
cursor = db.cursor()
# 执行 SQL 建表语句
cursor.execute(sql_create)
count = 1
for url in urls:
print(url)
text = get_html(url)
results = eval(text.replace('data_callback(', '')[:-1])
for result in results:
doc_url = result['docurl']
title = result['title']
post_time = result['time']
source = result['label'].strip()
try:
content = get_content(doc_url)
except:
continue
print(count, doc_url, title)
# 插入语句
sql = "INSERT INTO wangyi_tech (url,title,time,source,content) " \
"VALUES ('%s','%s','%s','%s','%s')" % (doc_url, title, post_time, source, content)
try:
# 执行 SQL 插入语句
cursor.execute(sql.replace('\n','\t'))
except:
print('Insert Error:', doc_url)
# 如果发生错误则回滚
db.rollback()
# 提交到数据库执行
db.commit()
count += 1
time.sleep(1)
time.sleep(2)
# 关闭数据库连接
db.close()
print('done')
if __name__ == '__main__':
url1 = ['http://tech.163.com/special/00097UHL/smart_datalist.js?callback=data_callback']
urls = url1 + ['http://tech.163.com/special/00097UHL/smart_datalist_0{}.js?callback=data_callback'.format(str(n))
for n in range(2, 10)]
main(urls)
运行结果

数据示例
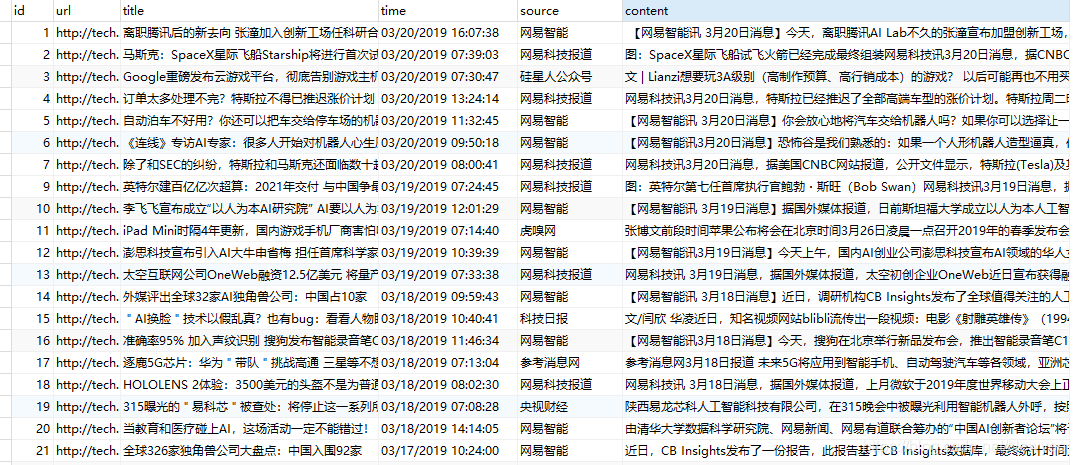
ps. get_content(doc_url) 获取文章全文对部分文章可能不适用或只获取到部分内容 (猜测可能是因为网易的频道或文章时间跨度比较大,网页结构不统一)
行文仓促,注释和讲解部分不够详尽,如有疑问欢迎留言交流讨论~~~


