应用场景
小明的老师要打印学生成绩单,于是制作了一份 Word 文档,每个学生的成绩单为一个表格,如下图所示:
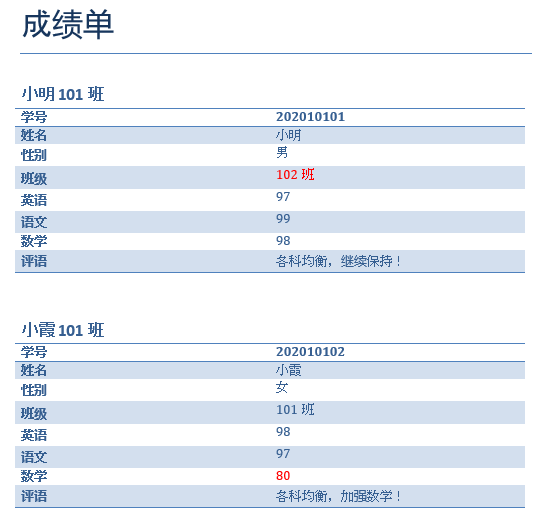 但是核对 Excel 中的成绩时发现存在一些错误,比如小明的班级、小霞的数学成绩:
但是核对 Excel 中的成绩时发现存在一些错误,比如小明的班级、小霞的数学成绩:
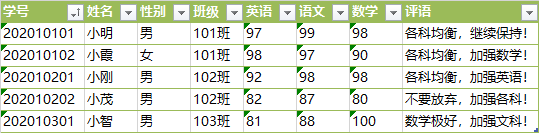 每个学生(逐行)每个字段(逐列)比对了一番苦不堪言,那我们可不可以用
每个学生(逐行)每个字段(逐列)比对了一番苦不堪言,那我们可不可以用 Python来帮帮老师呢?
作为无所不能的 Python 大法,这自然不在话下!
下面便介绍如何用 python-docx 读取 Word 文档中的表格数据并与 Excel 中的数据比对。
python-docx 介绍
python-docx是用于创建和更新 Microsoft Word(.docx)文件的 Python 库。
安装
python-docx 托管在 PyPI 上,可以很方便地用 pip 安装:
1
pip install python-docx
- 支持 Python 2.6、2.7、3.3、3.4(本文运行环境为 3.6,尚未发现安装和使用的异常)
- 会自动安装依赖库:lxml> = 2.3.2
示例
ps.注意在运行目录下准备一张图片:
image.png
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 导包
from docx import Document
from docx.shared import Inches
# 创建空白文档
document = Document()
# 添加标题
document.add_heading('Document Title', 0)
# 添加段落
p = document.add_paragraph('A plain paragraph having some ')
# 添加不同格式的文字
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
# 添加一级标题
document.add_heading('Heading, level 1', level=1)
# 添加不同样式的段落
document.add_paragraph('Intense quote', style='Intense Quote')
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph(
'first item in ordered list', style='List Number'
)
# 添加图片并设置大小
document.add_picture('image.png', width=Inches(1.25))
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
# 添加表格
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
# 添加分页
document.add_page_break()
# 保存文档
document.save('demo.docx')

需求实现
下面我们就可以借助 python-docx 来实现文章一开始的需求了,简单分为以下几步:
- 读取 Word 文档中的表格数据,即
read_docx_tables函数: a. 打开文档对象:document = Document(docx_file)b. 获取表格集,遍历每个表:for table in document.tables:c. 遍历所有行:for r in table.rows:d. 读取单元格中的值:k, v = cells[0].text, cells[1].text; value_dict[k] = v(这里针对==双列键值对型的表格==,数据存储为字典中的键值对) - 读取 Excel 数据 —— 本例使用
xlrd库读取test.xlsx文件,不做详解 - 判断 Excel 数据与 Word 数据是否匹配 —— 本例中数据一致则填充绿色,否则填充黄色并显示 Word 中的值
- 匹配与不匹配的数据分别用不同的格式写入新的 Excel 文件 —— 本例使用
xlsxwriter库生成test_mapped.xlsx文件,不做详解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import xlrd
import xlsxwriter
from docx import Document
docx_name = 'test.docx'
input_excel = 'test.xlsx'
output_excel = 'test_mapped.xlsx'
def read_docx_tables(docx_file):
"""
读取 Word 文档中双列键值对型的表格
:param docx_file: 文档文件名
:return: [{key1: value1, ...}, ...]
"""
# 创建文档对象,获得word文档
document = Document(docx_file)
# 读取表格集中的值
doc_tables_values = []
for table in document.tables:
value_dict = {}
for r in table.rows:
cells = r.cells
k, v = cells[0].text, cells[1].text
value_dict[k] = v
doc_tables_values.append(value_dict)
return doc_tables_values
def docx_vs_xlsx():
print('Running...')
docx_tables = read_docx_tables(docx_name)
# 读取旧的 Excel
bk = xlrd.open_workbook(input_excel)
sh = bk.sheet_by_index(0)
nrows = sh.nrows # 获取行数
ncols = sh.ncols # 获取列数
titles = sh.row_values(0) # 获取标题行
# 写入新的 Excel
workbook = xlsxwriter.Workbook(output_excel)
worksheet = workbook.add_worksheet()
cell_format_yellow = workbook.add_format({
'fg_color': '#FFFF00',
})
cell_format_green = workbook.add_format({
'fg_color': '#92D050',
})
# 边读边写
for row in range(nrows):
doc_values = []
if row != 0:
doc_values = docx_tables[row-1]
print(doc_values['姓名'])
for col in range(ncols):
xls_value = sh.cell_value(row, col)
if row == 0:
worksheet.write(row, col, xls_value)
continue
doc_value = doc_values[titles[col]]
# 数据一致则填充绿色,否则填充黄色并显示 doc_value
if xls_value == doc_value:
worksheet.write(row, col, xls_value, cell_format_green)
else:
worksheet.write(row, col, doc_value, cell_format_yellow)
print('Row', row + 2, end='\t')
workbook.close()
print('\rSucceeded!')
if __name__ == '__main__':
docx_vs_xlsx()
代码运行后便可得到黄绿标记的 test_mapped.xlsx,与原始表格对比图如下:
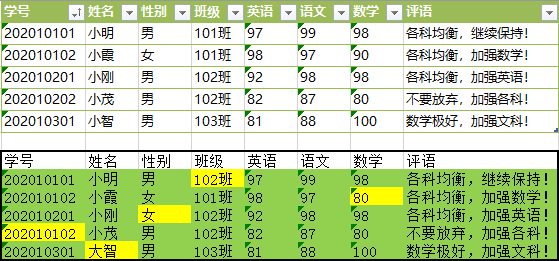 小明老师再也不用盯着两份文件“找不同”啦~~~
小明老师再也不用盯着两份文件“找不同”啦~~~
未完待续
- 本例 Word 中表格顺序与 Excel 中的行顺序对应一致(其实我也是用 python-docx 生成的 Word :wink:),实际应用时根据数据情况可先判断是不是目标表格再匹配具体数值
- 本例的 Word 为一个文档包含了多个表格,实际应用中也可以是每行 Excel 数据对应一个 Word 文档,依次打开文档读取指定的表格即可
- 本例仅考虑数据完全一致的情况,匹配规则还可以根据实际场景调整


